Share This Page
Measuring Clinical Performance
Published in the Physician Executive Journal November/December 2009
 The
Problem of Unreliable Methods
The
Problem of Unreliable Methods
Joint Commission standards calling for Focused (initial) and Ongoing Professional Practice Evaluation (FPPE/OPPE), which became effective in January 2008, seem to have given us a new set of buzzwords. Unfortunately, they have not reversed the widespread misunderstanding of what it takes to reliably evaluate clinical performance.
Our national study of peer review practices highlighted this problem. (1) Basically, we are using unreliable methods to evaluate performance and, thereby, losing much in the process.
This seems totally incongruous. Why would intelligent, scientifically trained professionals do this en masse and for so long? If we want to move on and do things better, it will be useful to first look at how we got where we are.
I believe we’re blind to the practice because, for the past 3 or 4 generations, that’s what we were taught to do by clinicians who we highly respected. We accept it as gospel. We were trained on what I’ll call the Quality Assurance or QA paradigm for peer review.
The QA Model vs. The QI Model
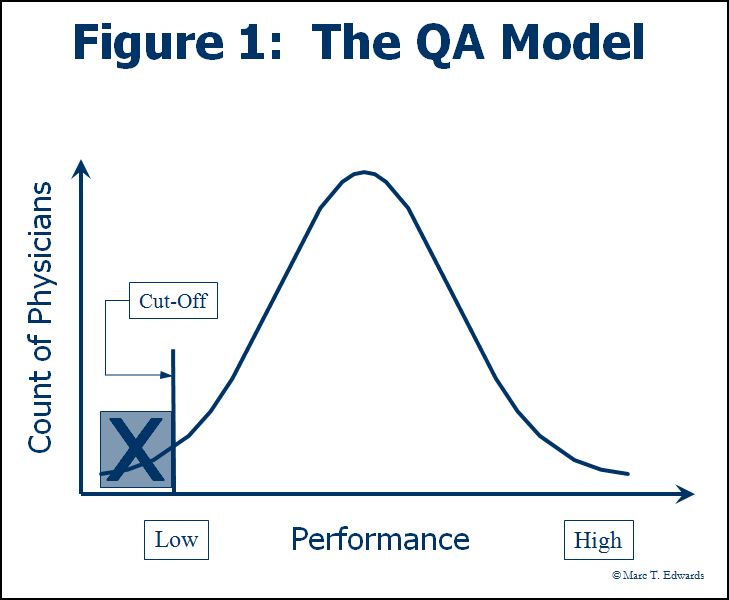
In the QA model (Figure 1), the process of peer review seeks to answer the question of whether or not substandard care occurred. It became an exercise in outlier management. Despite criticism, it strongly persists as part of our professional culture. (2) The QA model was further impaired by its reliance on “generic screens” to identify cases for review in which there was potential for substandard care. Generic screens were never adequately validated for this purpose, but became widespread in relation to the Joint Commission standards of the time. (3)
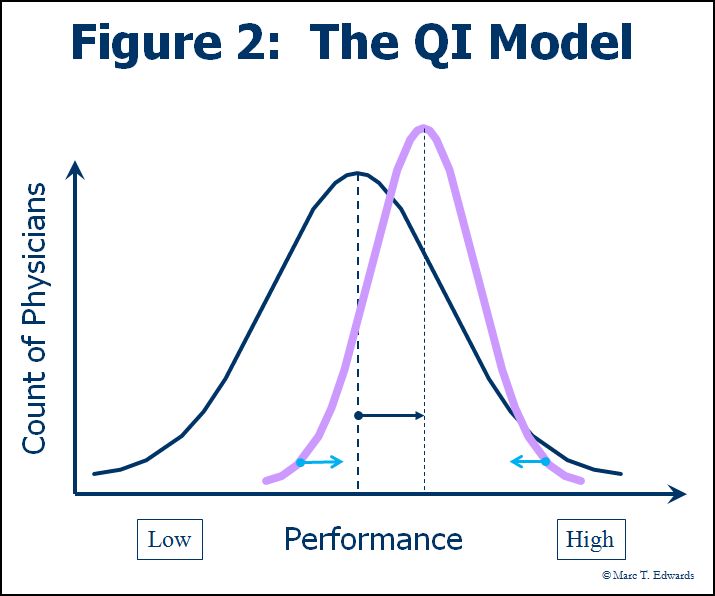
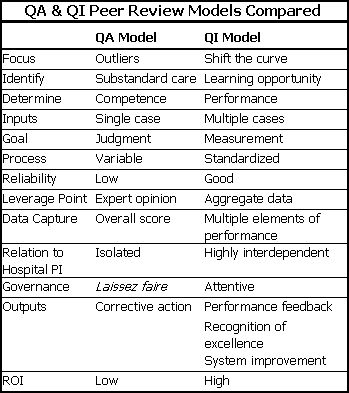
The QA model stands in stark contrast to the Quality Improvement (QI) model which the entire healthcare industry has finally come to embrace (Figure 2). The goal of QI is to “shift the curve” of performance. Key elements of the QI model include measuring performance, providing performance feedback, and reducing variation through process improvement. This table summarizes the major differences between the QA and QI models for peer review.
The QA model focuses on making a yes or no judgment about whether care was acceptable. These binary categories (sub-standard care and acceptable care) are established based on a “cut” point. The assessment (judgment) about whether the cut point has been reached is made using implicit and largely subjective criteria about what constitutes the professional standard of care. This is because, there are relatively few explicit, validated, objective criteria available to apply against the enormous range of clinical activity subject to peer review and the panoply of variables operative in any given case scenario.
The use of implicit criteria is not the problem. The real problem with the QA approach is that it skips two steps of scientific thinking.
What has been obscured and lost by this ingrained practice is the measurement of clinical performance.
Measurement Methodology
To fully appreciate this, we need to step back and take a contrasting look at how we behave as when selecting and using a clinical test. First, we look at the reliability of the test itself versus the available alternatives. Then, we look at the result of the test in relation to our a priori assumptions about the likelihood of a condition being present and our knowledge of the sensitivity and specificity of the test (Bayesian analysis). Lastly, we make a decision on how to interpret the test, i.e., to make the judgment about whether or not the condition is present, and how to proceed with next steps in the care of the patient. It should not matter whether the test under consideration measures a physical property (e.g., plasma glucose) on a continuous scale or an abstract concept (e.g., health status, depression, life stress, intelligence) on a constructed ordinal scale.
Many measurement scales have been constructed for use in education, the social sciences, psychology and healthcare. The field of measurement theory is very rich and directly applicable to the challenges of clinical performance measurement and evaluation. Streiner and Norman have written an excellent monograph introducing measurement theory as applied to healthcare. (4) The general design of measurement scales for abstract concepts is beyond the scope of this paper, but should be understood by those wishing to build their own tools for clinical performance measurement.
Reliability Defined
Let’s return to the question of measurement reliability. What is it? Reliability is a measure of a test’s ability to differentiate among subjects. This is a very important point. The general formula for reliability, which is at least a century old, is:
Reliability = Subject Variability / [Subject Variability + Measurement Error].
This ratio generates a number between 0 and 1. It is usually assessed in a specific context such as inter-rater or test-retest. The commonly used statistics are kappa and the intra-class correlation coefficient. The general formula tells us that reliability will be greater when measurement error is small and/or when subject variability is high on the dimension under consideration. Typically, rating methods for subjective judgments use the familiar, symmetrical Likert type scales (e.g., Strongly Agree, Agree, Neutral, Disagree, Strongly Disagree). Such scales force a choice among multiple levels or categories of a variable. They are not yes or no judgments. A greater number of categories make a test more reliable, because they augment the range of measured variation. This is true up to the point at which raters can’t differentiate the choices. Practically speaking, this limit is reached at about 10 intervals or categories.
Reliability vs. Agreement
Reliability is not the same as agreement between raters. In fact, agreement can be high, even when reliability is low. Streiner and Norman use medical student clinical performance ratings as their “classic” example of an unreliable test, in which everyone commonly receives an above average score. If all raters agree on the same above average rating in every case, agreement is perfect. Reliability is then zero, because no one is differentiated. They go on to suggest that such a situation calls for an asymmetrical scale with7 to 9 categories and more categories describing the range of above average performance.
Now, let’s apply these concepts to the process of peer review. What are the available tests and what is their reliability? It turns out that the unstructured implicit judgments of quality that prevail in the QA model have marginal inter-rater reliability (mean weighted kappa of 0.3). (5) In contrast, structured implicit review methods have achieved significantly better reliability, with kappa in the 0.4-0.7 range, a level which is generally considered adequate for aggregate comparisons. (5, 6)
The Practical Application
Structured review involves assessments of multiple elements of care (see the example below). Note that, according to Streiner and Norman’s analysis, this sample form could have been improved by incorporating a scale with more categories. My own experience with clients has born this out. Thus far, however, reported studies of structured implicit review used rating scales with 5 intervals from best to worst. Even so, Sanazaro and Worth have shown that as few as 5 cases are sufficient to reliably differentiate sub-par performance when such structured ratings are used. (7) Many more cases would be required if only a single aspect of performance is rated.
Figure 3: Sample Structured Rating Scale
cf: Rubin HR et al. Guidelines for Structured Implicit Review of Diverse Medical and Surgical Conditions. RAND; 1989 N-30066-HCFA.

In our national survey of peer review practices, we found that 38% of hospitals use structured forms to capture review data, but virtually none use a comparable rating scale. (1) Thus, almost universally, we are using unreliable methods to do peer review.
Moreover, we’re neglecting to apply the principles we use every day in our quality improvement work. First, we’re wasting the effort required to review and assess clinical care by capturing only a single outcome measure (standard of care), when we intuitively assessed so many other aspects in the process of arriving at our conclusion. Second, by failing to make adequate measurements of clinical performance, we lose the opportunity to aggregate data and make valid comparisons. Third, we miss the opportunity to “shift the curve” by providing rich performance feedback.
For a more detailed discussion, please see my whitepaper: The Peer Review Improvement Opportunity or my article in the Physician Executive Journal, Peer Review: A New Tool for Quality Improvement.
Use a Structured Review Process
The simple solution to improving case scoring methodology is to adopt a structured approach to recording peer review findings that uses rating scales with at least 7 intervals ranging from best to worst. We have the knowledge to do this. All we need is the will.
References
- Edwards MT, Benjamin EM. The process of peer review in US hospitals. J Clin Outcomes Manag 2009;(In Press).
- Berwick DM. Peer review and quality management: are they compatible? Qual Rev Bull. 1990;16(7):246-51.
- Sanazaro PJ, Mills DH. A critique of the use of generic screening in quality assessment. JAMA 1991;265(15):1977-1981.
- Streiner DL, Norman GR. Health Measurement Scales: A Practical Guide to their Development and Use. 3rd ed. New York, NY: Oxford University Press; 2003.
- Goldman RL, Ciesco E. Improving peer review: alternatives to unstructured judgments by a single reviewer. Jt Comm J Qual Improv 1996;22(11):762-9.
- Hayward RA, McMahon LF, Bernard AM. Evaluating the care of general medicine inpatients: How good is implicit review? Ann Intern Med. 1993;118(7):551-557.
- Sanazaro PJ, Worth RM. Measuring clinical performance of internists in office and hospital practice. Med Care 1985;23(9):1097-1114.
Links
- Clinical Peer Review Process Improvement Resources
- The QI Model for Clinical Peer Review
- The History of the QA Model
- Clinical Peer Review Program Self-Assessment Inventory
- Ideal Clinical Peer Review Process Collaborative
- Normative Peer Review Database Project
Whitepapers
Products and Services
- The Peer Review Enhancement ProgramSM
- PREP-MSTM: Program Management Software
- My PREPTM: The Complete Toolkit for Improvement
- DataDriverSM
- Client Testimonials
- Typical Client Results